Overview
This vignette describes the likelihood and parameterisation used in the STAGE model.
STAGE is a hierarchical Bayesian generative model designed to estimate a transition point on variable between two classes—for example, the length at which individuals transition from immature to mature. The model produces a posterior distribution for , representing the value of at which the probabilities and are equal. The model can also be used to derive other useful quantities (such as class probabilities ).
Conceptually, STAGE is a Bayesian generative classifier for estimating a transition point (e.g. length at maturity). Each class is fit with an asymmetric plateau–Gaussian density:
- the lower class has a uniform plateau followed by a Gaussian tail down into the transition,
- the higher class has a Gaussian tail up out of the transition followed by a uniform plateau.
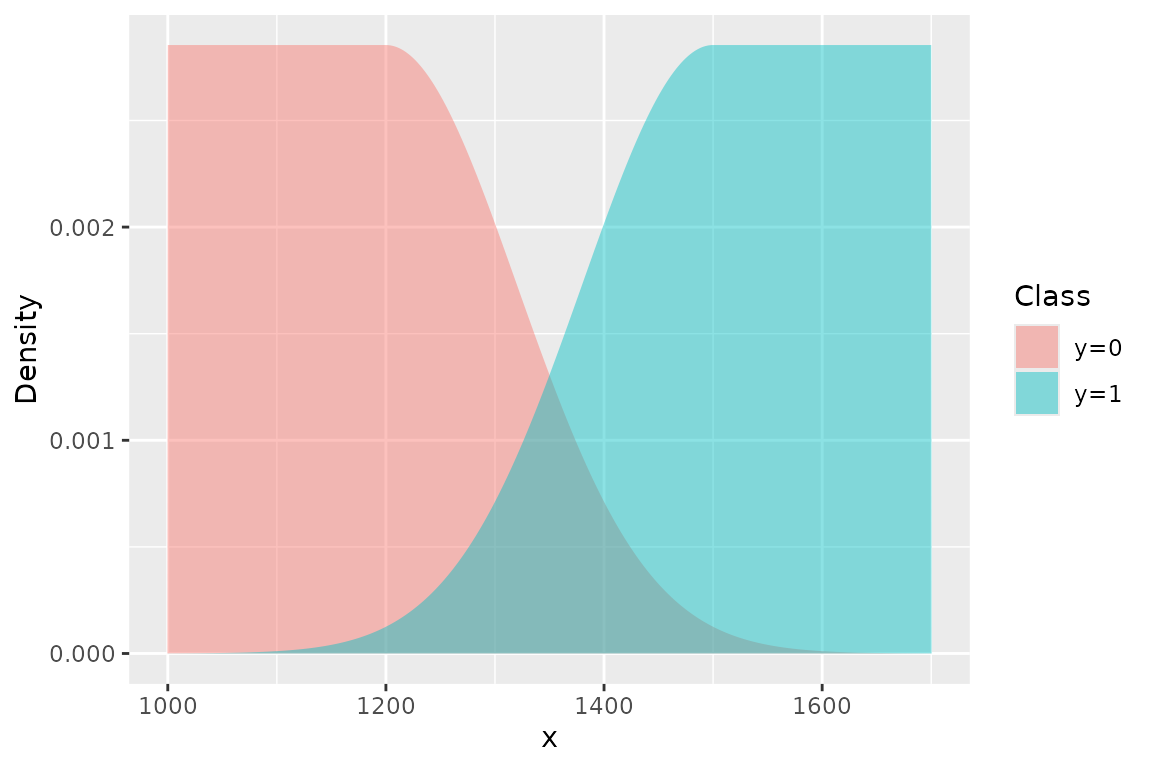
This construction focuses inference on the overlap region and prevents distant observations (e.g. very small immatures, very large matures) from unduly influencing the transition point.
The central idea is to model each class with a piecewise density that combines a uniform plateau in regions far from the transition, and a Gaussian tail in the transition region. The left group () is modelled with a uniform on the left that begins at the lower truncation value . The distribution remains flat until it approaches the transition range, at which point the distribution declines according to a Gaussian. The right group () is a mirror image of the left—it increases according to a Gaussian distribution and then levels off to a uniform, terminating at the upper truncation value .
The model focuses inference on the transition zone, where the values of of the two classes overlap, and down-weights observations that are biologically uninformative because they are far away from the transition point.
The uniform–Gaussian pdf used here is adapted from a plateau proposal distribution combining a uniform and two Gaussians described by Lau & Krumscheid (2022).
Model summary
We observe pairs for , where
- is a continuous covariate (e.g., length), truncated to an interval , and
- is a binary indicator of state (e.g., immature / mature).
The model assumes that the distribution of conditional on state is piecewise:
- For (immature individuals), the distribution of is approximately uniform up to a point , after which it follows a Gaussian decay.
- For (mature individuals), the distribution is Gaussian below a point , and uniform above up to the upper truncation .
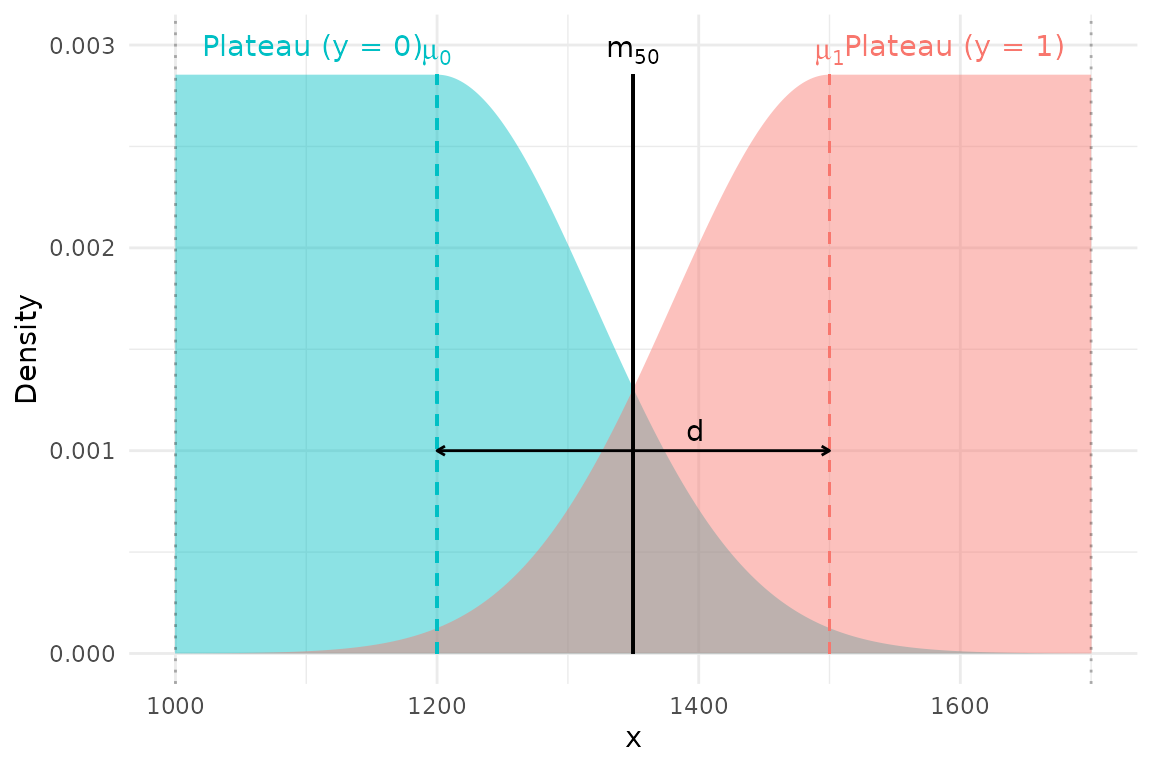
The transition point is the value of where the probability of observing either class is equal:
Additional parameters govern the width and sharpness of the transition:
- controls the distance between and (the width of the transition region),
-
(denoted
sigma_xin the Stan code) controls the spread (standard deviation) of the Gaussian tails.
By allowing different behaviours on either side of the transition, the model can capture asymmetric transition patterns: the immature class can decline towards the transition at a different rate than the mature class rises out of it.
This is particularly useful in settings where:
- the boundary between classes is not sharp, and
- the data exhibit gradual overlap between the two classes.
Likelihood
The likelihood is built from two unnormalised log-density functions for the two classes. We work on the log scale for numerical stability and then subtract log-normalising constants to obtain valid densities.
Let and denote the unnormalised log-densities for and , respectively. The corresponding (unnormalised) densities are .
We restrict attention to the truncated interval ; the densities are zero outside this range.
Lower class ()
For , the unnormalised piecewise log-density is
Here:
- the plateau region has constant log-density 0 (density 1),
- the tail region decays according to a Gaussian kernel.
Any constant could be added to without changing the posterior; we fix the plateau at 0 so that the plateau density is 1 after exponentiation.
Higher class ()
For , the unnormalised log-density is
Now:
- the Gaussian tail is below , and
- the plateau covers the upper region .
In both cases we have a plateau–Gaussian shape: a flat density where the class “dominates” and a Gaussian tail in the transition region where the other class is present.
Normalisation constants
To convert into proper probability density functions on , we divide by constants and chosen so that the densities integrate to 1.
For the immature class ():
For the mature class ():
Intuitively:
- and are the widths of the uniform plateaus,
- is the contribution from the half-Gaussian tail.
The corresponding log-likelihood contribution for observation is
Summing over all observations,
which is exactly the likelihood implemented in the Stan code used by
fit_stage().
Prior specification
The priors reflect prior beliefs about plausible transition points and transition widths in typical length-at-maturity problems. In practice, these are defaults that should be adapted to the scale of the data and prior biological knowledge.
By default, STAGE uses weakly informative normal priors:
-
Transition point
(Stan parameter
m50):
which centres the transition point around 1300 (mm) with moderate uncertainty.
- Transition width :
which allows the width of the overlap region to vary around 100 units with a wide spread. Note that is the distance between the class-specific Gaussian centres.
-
Gaussian spread
(Stan parameter
sigma_x):
representing prior beliefs about the scale of variability in the transition tails.
Because
and sigma_x are constrained to be positive in the Stan
model, their Normal priors are effectively half-Normal
distributions (the prior mass below zero is folded onto the positive
half).
In practice, you should adapt these priors to your scale (e.g.,
lengths, ages) and prior biological knowledge. The STAGE implementation
allows you to pass in hyperparameters via helper functions such as
stage_priors().
Transformed parameters
The Gaussian “centres” for the two classes are defined in terms of the transition point and the width parameter :
Thus:
- controls the distance between the immature and mature Gaussian means,
- is the midpoint between them.
From class densities to class probabilities (Bayes rule)
The likelihood above defines the class-conditional densities and on , obtained by normalising the unnormalised densities with the constants .
To obtain the probability that an individual with a particular value is in the higher class (), we use Bayes rule:
and similarly
where and are the prior class probabilities (e.g., prior probabilities of being immature or mature before seeing ).
In many applications, such as estimating length-at-maturity, we are interested in a transition point that is not driven by sample sizes or prevalence, so it is natural to use equal class priors, . In that case, Bayes rule simplifies to
These are the class probabilities that the STAGE model uses for prediction, and they are what you see when you plot as a function of .
Connection to
By definition, the transition point is the value of where the two classes are equally probable:
Using Bayes rule with equal class priors, this equality is equivalent to
i.e. the two normalised class densities are equal at .
Why is the midpoint between and . In the transition region (), both unnormalised densities take Gaussian form:
Since both Gaussians share the same , the unnormalised densities are equal at the arithmetic midpoint . With equal class priors, the normalising constants and cancel in the likelihood ratio, so the 50% crossing point is exactly regardless of the survey bounds and . This is the key invariance property: changing the sampling domain does not shift the estimated transition point.
Relationship to the stage implementation
In the stage package:
- The single-population model directly samples
m50(),d, andsigma_x(). The transition point is a primary sampling parameter, not a derived quantity. - The multi-population (hierarchical) model introduces population-specific transition points via a random-effects structure: where is the global mean transition point, are standard-normal effects, and is the population-level standard deviation.
The Stan code used in fit_stage() is a direct
implementation of the likelihood and parameterisation described
above.
Future vignettes will provide a more detailed walk-through of the Stan code and extensions such as alternative priors and model comparison.